GPT-3 vs. Rasa chatbots
Table of Contents
Richard Trevithick’s locomotive — the GPT-3 of the early 19th century (Shutterstock.com)
Comparing the performance of GPT-3 and a custom-trained Rasa chatbot.
In 1829, an event took place that unleashed a technological revolution. At the Rainhill Trials a group of steam locomotives squared off to determine which one could win a series of tests of speed, strength and reliability. The winning machine, Rocket, not only blew away its competition at the trials, it also set the direction for steam locomotive development for the following century.
What does all this have to do with GPT-3, the transformer language model that OpenAI made available in a limited beta starting in June? Some reviewers have heralded GPT-3 as the first glimpse of artificial general intelligence, while others are calling it a massive lookup table. I don’t think GPT-3 is AGI, but I do think the approach used in GPT-3 will be transformative. Using massive computing power and a huge training suite, OpenAI has created a model that is genuinely general-purpose. By drawing comparisons to the dawn of the railway age we can put GPT-3 in context and see its impact more clearly.
In this article I will describe a simple test that I did to compare GPT-3’s performance with a Rasa chatbot. This test was certainly no Rainhill Trials, but I think the results do shed some light on the role that massive transformer models like GPT-3 will play in the future. I will argue that GPT-3 isn’t the AI equivalent of Rocket, but it just might play the role of the locomotives designed by Richard Trevithick in the decades prior to the Rainhill Trials. Trevithick’s machines were slow and so heavy that they destroyed their tracks. However, despite their flaws, these locomotives had the right essential ingredients and they paved the way for the world-changing success of Rocket.
A direct comparison of GPT-3 and a Rasa chatbot
Access to the beta for GPT-3 is still limited. The standard application process did not work for me, but I followed the advice in this video, and I was granted access a few days later.
Once I had access to GPT-3 I wanted to do a simple test to compare its capabilities with an existing application. Earlier this year I created a chatbot in Rasa to answer general questions about movies. This chatbot took 4 months to develop and was explicitly trained on an extensive movie dataset. For the comparison between GPT-3 and the Rasa chatbot, I picked 7 random questions from the regression test set for the chatbot. I compared the answers that Rasa and GPT-3 provided for these questions to get the results of the test.
Test results for Rasa
To run the test with the Rasa chatbot, I started the trained Rasa model using the “rasa shell” command and interactively entered the questions. Here are the results, with my input in bold and the chatbot’s responses in regular font:

Test responses from the Rasa chatbot
The Rasa chatbot got 6 of 7 questions right:
- The answer for the “list comedy vampire movies” question was incorrect. I tried several different variations of the question but the results were the same.
- I counted the answer for the cast of The Ten Commandments as technically correct because the list returned by Rasa was indeed made up of cast members from the movie. However, the answer was not as expected since the two most memorable stars, Charlton Heston and Yul Brynner, were omitted.
Test results for GPT-3
To run the test with GPT-3, I selected the Q&A preset in the Playground tab of the GPT-3 dashboard and entered the same questions as I had entered in the Rasa command line interface. Here are results, right out of the box, with my input in bold and GPT-3’s answers in regular font:
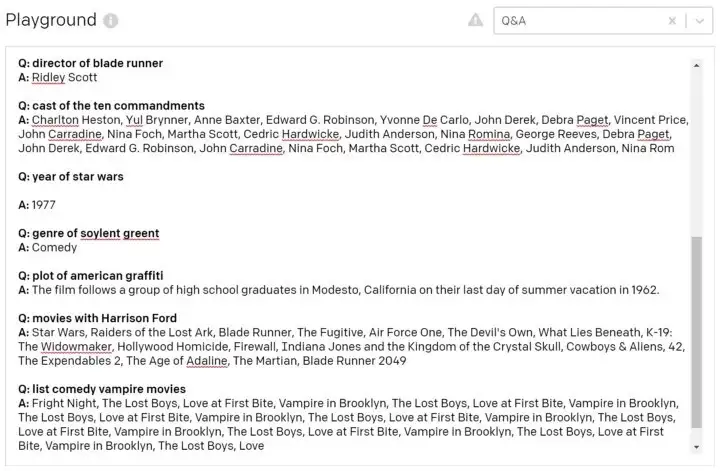
Test responses from GPT-3
GPT-3 got 5 of 7 questions completely correct. Of the two remaining test cases:
Soylent Green is arguably funny — “Soylent Green is People!” — but I think that GPT-3 got it wrong by labelling this movie as a comedy.
GPT-3 had a good answer for the “list comedy vampire movies” question, but it repeated a subset of the correct answer several times. Also, Fright Night was by far the best of the comedy vampire sub-genre, so I was disappointed that GPT-3 omitted it from the repetition.
I decided to see what happened when I provided a few examples to help GPT-3 to answer the questions it didn’t answer correctly.